This post is a summary, the full writeup with data is here (PDF). The texts are quite similar, so if you plan to read the paper you can skip this post.
Following pointer
acceleration in libinput - an analysis, we decided to run an
actual userstudy to gather some data on how our acceleration
behaves, and - more importantly - test if a modified acceleration
method is better.
We developed two new pointer acceleration methods (plus the one already in
libinput). As explained previously, the
pointer acceleration method is a function mapping input speed of a
device into cursor speed in pixels. The faster one moves the mouse,
the further the cursor moves per "mickey" (a 1-device unit
movement). In a simplest example, input deltas of 1 may result in a
1 pixel movement, input deltas of 10 may result in a 30 pixel
movement.
The three pointer acceleration methods used in this study were
nicknamed:
smooth:- A shortening of "smooth and simple", this
method is
used in libinput 0.5 as well as in the X.Org stack since
~2008.
stretched:- a modification of 'smooth' with roughly
the same
profile, but the maximum acceleration is applied at a higher
speed. This
method was developed by Hans de Goede and very promising in
personal
testing.
linear:- a linear acceleration method with a roughly
similar
speed-to-acceleration profile as the first two. This method was
developed to
test if a simple function could achieve similar results, as the
more complex
"smooth" and "stretched" methods.
The input data expected by all three methods is in units/ms. Touchpad devices are normalised to 400 dpi, other devices are left as-is. It is impossible to detect in software what resolution a generic mouse supports, so any acceleration method differs between devices. This is intended by the manufacturer, high-resolution devices are sold as "faster" for this reason.
 The three pointer acceleration methods
The three pointer acceleration methods
As the graph shows, the base profile is roughly identical and the
main difference is how quickly the maximum acceleration factor is
reached.
Study description
Central component was a
tool
built on
libinput that displays a full-screen white window, with a
round green target. Participants were prompted by GTK dialog boxes on the
steps to take next. Otherwise the study was unsupervised and self-guided.
The task required participants to click on a round target with a
radius of 15, 30 and
45 pixels. Targets were grouped, each "set" consisted of 15 targets
of the
same size. On a successful click within the target, a new target
appeared
on one out of 12 possible locations, arranged in a grid of 4x3 with
grid points 300 pixels apart. The location of the target was
randomly selected
but was never on the same location twice in a row.
 Screenshot of the study tool
with the first target (size 45) visible.
Screenshot of the study tool
with the first target (size 45) visible.
Each participant was tested for two acceleration methods, each
acceleration method
had 6 sets of 15 targets (2 sets per target size, order randomised).
The two acceleration methods were randomly selected
on startup, throughout the study they were simply referred to as
"first" and "second" acceleration method with no further detail provided.
Acceleration changed after 6 sets (participants were informed about it), and
on completion of all 12 sets participants had to fill out a questionnaire and upload the data.
Statistical concepts
A short foray into statistics to help explain the numbers
below. This isn't a full statistics course, I'm just aiming to explain the
various definitions used below.
The mean of a dataset is what many people call the average:
all
values added up divided by the number of values. As a statistical
tool, the
mean is easy to calculate but is greatly affected by outliers. For
skewed
datasets the median is be more helpful: the middle
value of the data array (array[len/2]). The closer the mean and
the median are together, the more symmetrical the distribution
is.
The standard deviation (SD) describes how far the data
points
spread from the median. The smaller the SD, the closer together are
the data
points. The SD is also used to estimate causality vs randomly induced sampling errors.
Generally, if the difference between two items is more
than 2
standard deviations, there's a 95% confidence that this is a true
effect, not
just randomness (95% certainty is a widely accepted standard in this domain).
That 95% directly maps
to the
p-value you may have seen in other studies. A p-value of
less than 0.05 equals a
less than 5% chance of random factors causing the data differences.
That
translates into "statistically significant".
The ANOVA method is a standard statistical tool for studies
like ours.
(we're using one-way ANOVA only here, Wikipedia has an example here).
If multiple sets of samples differ in only a single factor
(e.g. pointer
acceleration method), we start with the so-called Null-Hypothesis of
"the factor has no influence, all results are the same on average".
Our goal is
to reject that hypothesis so we can say that the factor did
actually change things. If we cannot reject the Null-Hypothesis,
either our
factor didn't change anything or the results are caused by random
influences.
The tools for ANOVA compare the mean value within each sets to the
mean value
differences across the sets and spit out a p-value. As above, a
p-value less than 0.05 means greater than 95% confidence that the
Null-Hypothesis can be rejected, i.e. we can say our factor did
cause those
differences.
One peculiarity of ANOVA is that the sample sets have to be the same
size. This affects our samples, more see below.
Study participants
An email was sent to three Red Hat-internal lists with a link to the study
description. One list was a specific developer list, the other two list were
generic lists. As Red Hat employees, participants are expected to
be familiar with Linux-based operating systems and the majority is more
technical than the average user. The data collected does not make it possible
to identify who took part in the study beyond the information provided in the
questionnaire.
44 participants submitted results, 7 left-handed, 37 right-handed
(no ambidextrous option was provded in the questionnaire). Gender distribution
was 38 male, 6 female. Mean age was 33.3 years (SD 6.7) and participants had
an mean 21.2 years of experience with mouse-like input devices (SD 4.9) and
used those devices an average 58.1 hours per week (SD 20.0).
As all participants are familiar with Linux systems and thus exposed
to the smooth acceleration method on their workstations, we expect a bias
towards the smooth acceleration method.
Study data
Data was manually checked and verified, three result files were discarded for
bugs or as extreme outliers, leaving us with 41 data files.
The distribution of methods in these sets was: 27 for smooth, 25 for stretched and
30 for linear.
The base measurement was the so-called "Index of Difficulty" (ID), the number
obtained by distance-to-target/width-of-target. This index gives an indication
on how difficult it is to hit the target; a large target very close is easier
to hit than a small target that is some distance away.
 Illustration of the Index of Difficulty for a target.
Illustration of the Index of Difficulty for a target.
In hindsight, the study was not ideally suited for evaluation based on ID. The
targets were aligned on a grid and the ID based on the pointer position was
very variable. As is visible in the
graph below, there are few clear dividing lines to categorise the targets based on
their ID. For the evaluation the targets were grouped into specific ID groups:
ID < 4.2, ID < 8.4, ID < 12.9, ID < 16.9 < ID < 25 and ID
> 25. The numbers were selected simply because there are clear gaps between the
ID clusters. This division results in uneven group sizes,
(I ran the same calculations with different group numbers, it does not have any real impact on the results.)
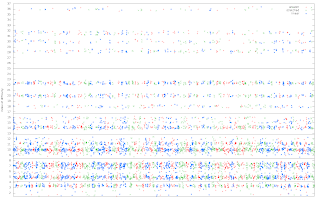 ID for each target with the divider lines shown
ID for each target with the divider lines shown
The top ID was 36.44, corresponding to a 15px radius target 1093 pixels away, the
lowest ID was 1.45, corresponding to a 45px radius target 130 pixels away.
 Number of targets per ID group
Number of targets per ID group
As said above, ANOVA requires equal-sized sample sets. ANOVA was performed separately between the methods (i.e. smooth vs stretched, then smooth vs linear, then stretched vs linear). Before each analysis, the two data arrays were cut to be of equal length. For example, comparing smooth and stretched in the ID max group shortened the smooth dataset to 150 elements. The order of targets was randomised.
Study Results
The following factors were analysed:
- Time to click on target
- Movement efficiency
- Overshoot
Time to click on target
Time to click on a target was measured as the time between displaying the
target and clicking on it. This does not take reaction time into account, but
there is no reliable way of measuring reaction time in this setup.
 Mean time to click on target
Mean time to click on target
As is visible, an increasing ID increases the time-to-click. On a quick
glance, we can see that the smooth method is slower than the other two in most
ID groups, with linear and stretched being fairly close together. However,
the differences are only statistically significant in the following cases:
- ID 8.4: linear is faster than smooth and stretched
- ID 12.9: linear and stretched are faster than smooth
- ID 25: linear and stretched are faster than smooth
In all other combinations, there is no statistically significant difference between the three methods, but overall a slight advantage for the two methods stretched and linear.
Efficiency of movement
The most efficient path from the cursor position to the target is a straight
line. However, most movements do not follow that straight line for a number of
reasons. One of these reasons is basic anatomy - it is really hard to move a
mouse in a straight line due to the rotary action of our wrists. Other reasons
may be deficiencies in the pointer acceleration method. To measure the
efficiency, we calculated the distance to the target (i.e. the straight line)
and compared that to all the deltas added up to the total movement. Note that
the distance is to the center of the target, whereas the actual movement may
be to any point in the target. So for short distances and large targets, there
is a chance that a movement may be less than the distance to the target.
 Straight distance to target vs. movement path shows the efficiency of movement.
Straight distance to target vs. movement path shows the efficiency of movement.
The efficiency was calculated as movement-path/distance, then normalised to a percent value. A value of 10 thus means the movement path
was 10% longer than the straight line to the target centre).
 Extra distance covered
Extra distance covered
Stretched seems to perform better than smooth and
linear in all but one ID group and smooth performing worse than linear in
all but ID group 4.2. Looking at the actual values however shows that the
large standard deviation prevents statistical significance. The differences
are only statistically significant in the following cases:
- ID 4.2: stretched is more efficient than smooth and linear
In all other combinations, there is no statistically significant difference between the three methods.
Overshoot
Somewhat similar to the efficiency of movement, the overshoot is the distance the
pointer has moved past the target. It was calculated by drawing a
line perpendicular to the direct path from the pointer position to the target's
far side.
If the pointer moves past this line, the user has overshot the target. The
maximum distance between the line and the pointer shows how much the user
has
overshot the target.
 Illustration of pointer overshooting
the target.
Illustration of pointer overshooting
the target.
The red line shows the amount the pointer has
overshot the target.
Overshoot was calculated in pixels, as % of the distance and as % of the actual
path taken. Unsurprisingly, the graphs look rather the same so I'll only put one up here.
 Overshoot in pixels by ID group
Overshoot in pixels by ID group
As the ID increases, the amount of overshooting increases too. Again the
three pointer acceleration methods are largely the same, though linear seems
to be slightly less affected by overshoot than smooth and stretched. The
differences are only statistically significant in the following cases:
- ID 4.2: if measured as percentage of distance, stretched has less overshoot than linear.
- ID 8.4: if measured as percentage of movement path, linear has less overshoot than smooth.
- ID 16.8: if measured as percentage of distance, stretched and linear have less overshoot than smooth.
- ID 16.8: if measured as percentage of distance, linear has less overshoot than smooth.
- ID 16.8: if measured in pixels, linear has less overshoot than smooth.
In all other combinations, there is no statistically significant difference between the three methods.
Summary
In summary, there is not a lot of difference between the three methods, though smooth has no significant advantage in any of the measurements. The race between stretched and linear is mostly undecided.
Questionnaire results
The above data was objectively measured. Equally important is the subjective
feel of each acceleration method. At the end of the study, the following 14
questions were asked of each participant, with answer ranges in a 5-point
Likert scale, ranging
from "Strongly Disagree" to "Strongly Agree".
- The first acceleration method felt natural
- The first acceleration method allowed for precise pointer control
- The first acceleration method allowed for fast pointer movement
- The first acceleration method made it easy to hit the targets
- I would prefer the first acceleration method to be faster
- I would prefer the first acceleration method to be slower
- The second acceleration method felt natural
- The second acceleration method allowed for precise pointer control
- The second acceleration method allowed for fast pointer movement
- The second acceleration method made it easy to hit the targets
- I would prefer the second acceleration method to be faster
- I would prefer the second acceleration method to be slower
- The two acceleration methods felt different
- The first acceleration method was preferable over the second
The figure below shows that comparatively
few "strongly agree" and "strongly disagree" answers were given, hinting
that the differences between the methods were small.
 Distribution of answers in the
questionnaire
Distribution of answers in the
questionnaire
Looking at statistical significance, the questionnaire didn't really provide
anything of value. Not even the question "The two acceleration methods felt
different" provided any answers, and the question "The first acceleration
method was preferable over the second" was likewise inconclusive. So the
summary of the questionnaire is pretty much: on the whole none of the methods
stood out as better or worse.
 Likert frequencies for the question of which method is preferable
Likert frequencies for the question of which method is preferable
Summary
Subjective data was inconclusive, but the objective data goes slightly in
favour of linear and stretched over the current smooth method. We didn't have
enough sample sets to analyse separately for each device type, so from a
maintainer's point of view the vote goes to linear. It allows replacing a
rather complicated pointer acceleration method with 3 lines of code.























